K8S 崩溃排查
记录一次 K8S 意外崩溃,修复思路,和复盘。
集群规格:
| 节点名 | 规格 | 说明 |
|---|---|---|
| Master-01 | 2 CPU, 4 GB | 控制节点(开启允许部署应用) |
| Node-01 | 4 CUP, 8 GB | 运行节点 |
| Node-02 | 4 CPU, 8 GB | 运行节点 |
安装 Ranucher 导致节点内存不足
崩溃起因为,使用 Helm chart 在 K8S 集群上部署 Rancher 。 安装后,初始状态一切正常,可以看到 local 集群,并进行简单管理。20分钟左右,其中一个 node 内存持续飙升, 导致重启。 集群开始调度 pod 到另外一个 node, 导致另外一个 node 内存飙升。出现雪崩效应。 Master 节点 CPU 使用率 100%。整个集群开始不响应任何请求。
修复思路
因集群上Pod大部分处在内存不足,停止,重启的过程。 无法使用 kubeadmin dashboard 通过 Web 管理集群。仅能通过控制节点上的 kubectl 来链接 K8S,效率低下。所以,先找到一个高效管理的工具, 对集群进行观测。再通过观测结果,做出相应修复方案,并执行。
高效的 K8S 终端管理工具 - K9S
K9S 是一套运行在命令行内的管理工具,使用习惯于 VIM 类似。通过K9S可以快速查看集群状况,在终端环境下可以高效运维集群。
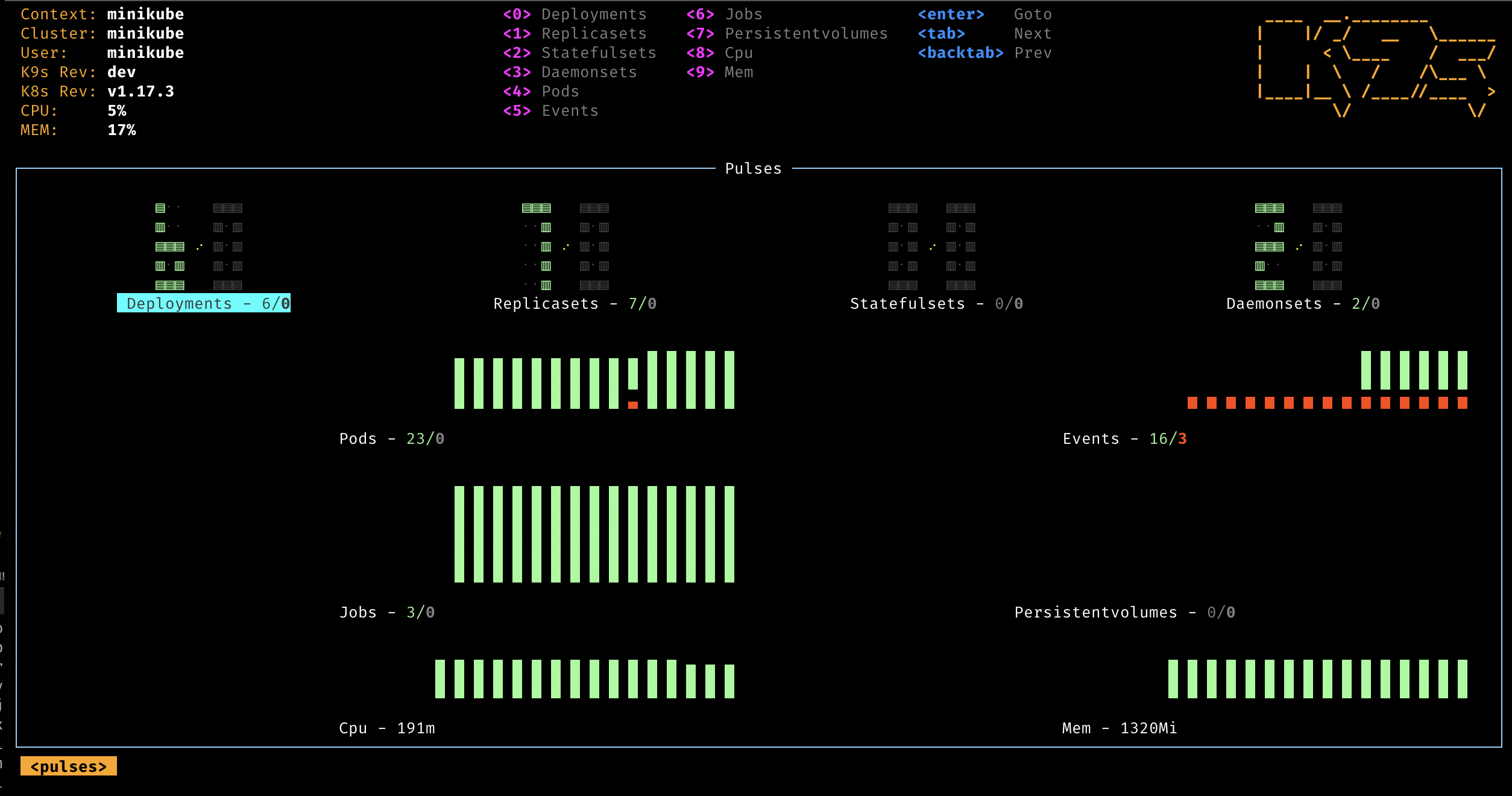
观测问题
在安装 K9S 之后, 通过观测发现 Helm chart 安装的 Rancher,带有全部特性包括多集群管理的 Fleet 特性。因为这些重量级的特性,导致集群内 Node 节点内存始终会被占满,导致重启。 发现了问题,也有了大致的解决问题的方向 —— 将 Rancher 从集群内清除!!!
修复方案
因为本身集群是用来做实验的测试集群,所以并不要求持续可用。 经过与同事讨论,方案有三个。
方案一:重置三台虚拟机,使用 RKE 重新拉起
方案简单粗暴。对于临时测试集群来说算是一种一了百了的高效方案。
优势:使用 RKE 可以快速拉起一套 K8S 集群,不需要太多多人工干预。同时,可以再体验一下 RKE 管理的K8S。
劣势:之前群上的一些应用需要重新安装。例如:ELK 全家桶,Nacos 等等。。。
方案二:从服务器上产掉K8S,通过 Kubeadmin 手动拉起
方案挑战较多。首先,要清理K8S 的残留文件。其次,手动拉起虽然有脚本支持,但也避免不了一些意外情况。
优势:可以演练一下产掉 K8S,重新定制化手动拉起的过程。
劣势:周期较长,有因为未清理干净,从而导致再次安装出现意外情况的可能。
方案三:手动清理 Rancher Stack
方案对现有集群影响最小。
优势:影响最小,可以通过逐个删除 Rancher Stack 的 Namespace 来完成资源删除。可以演练生产环境时,不能删除集群的情况。
劣势:有一些挂掉的 K8S 服务需要重新启动,并关联。
选择方案,并修复
既然是测试集群,本着折腾的原则。决定先采用__方案三__演练一下生产环境不能删除集群时的灾难恢复。
删除 Rancher Stack
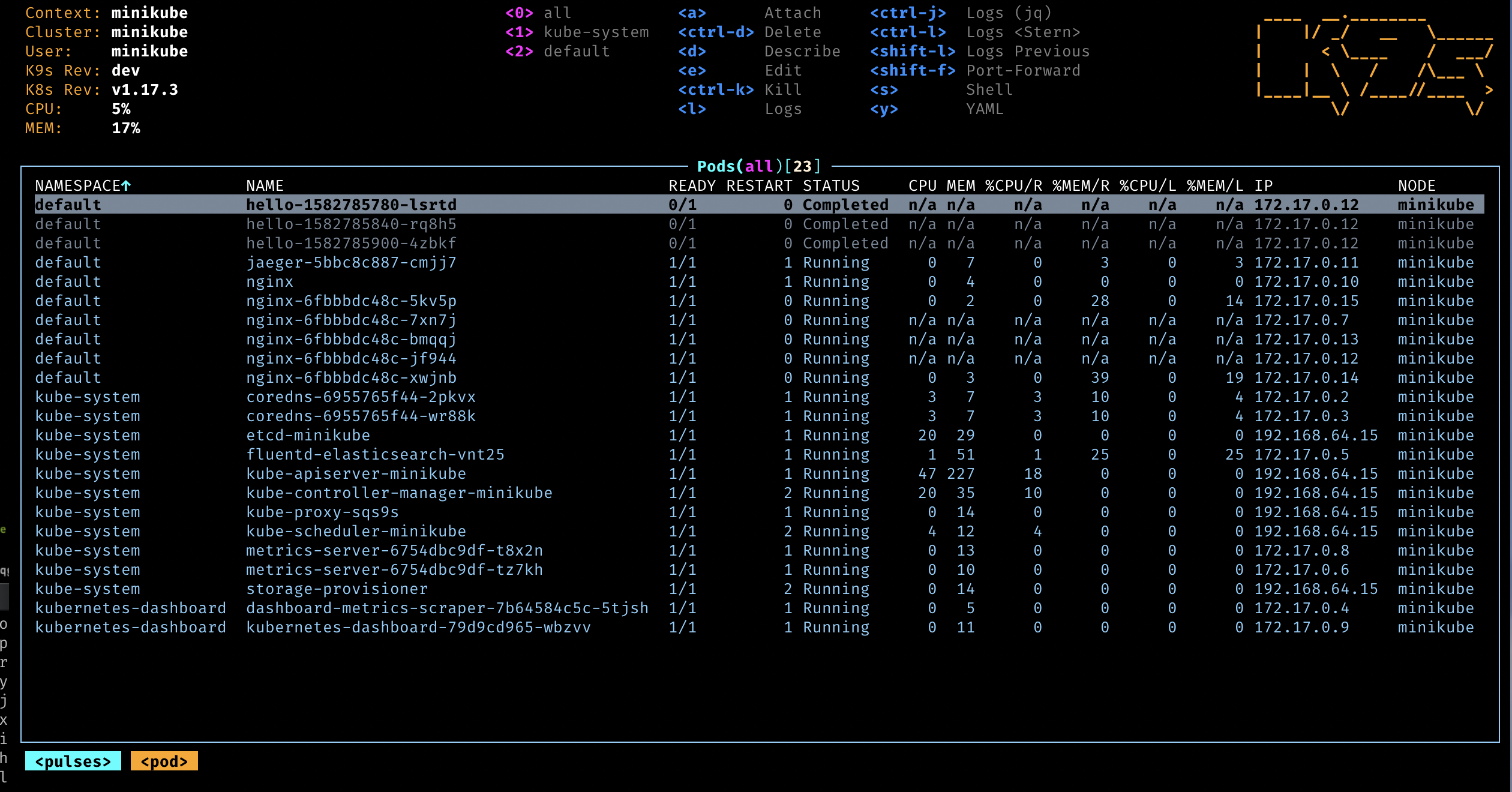
删除过程使用 K9S 非常简单高效。通过,namespece 视图选取相应的 namespace 使用 ctrl+d 快捷键即可启动删除操作。
等待 K8S 自愈
因为控制节点仅仅是 CPU 拉满,当 Rancher Stack 被逐渐删除后,控制节点开始恢复运转。 期间,Node-01 因始终无法接到清理指令,一直无法恢复,只能通过阿里云控制台强行重启。
最终,所有节点恢复运转,控制节点开始重新调度上层应用。
手动恢复操作
集群开始运行后,出现了以下问题几个问题。
Nacos 无法创建 endpoint
错误信息: the object has been modified; please apply your changes to the latest version and try again
经过排查得到官网说明:由于 etcd restore 之后,在重启 kube-apiserver 之前,控制平面各个组件缓存中的 Object 版本跟 etcd 备份中不一致。解决方法是是在 etcd restore 之后,重启控制平面所有组件。
通过 k9s 手动重启了所有 kube-system 下的 pod。⚠️注意:要从 pod 视图逐一删除pod。
Nacos 数据丢失
Nacos 重新启动后,之前的数据丢失,手动将本地保存的 Config 和 Namespace 恢复。 这个原因带排查,初步猜测原因是 Node 挂掉后,mysql Pod 被调度到另外一个节点,并重新初始化了数据库。或是,在恢复 Nacos 过程中失误删掉了数据库。
手动拉起 Kafka
集群正常启动后,发现日志没有进去 elasticsearch。 因为,之前 Kafka 是部署在 K8S 集群之外的 Node-01 上。所以,需要手动在 Node-01 上通过 docker-compose 启动。
一切恢复
经过一番折腾,在没有删除集群的情况下,将服务逐一恢复。历时 6 个小时,如果是真正的线上问题,已经可以定级为__严重故障__。
所以,需要复盘一下。
复盘
关键问题点
- 在使用 Helm 安装 Rancher 之前,虽然检查过 Pre-requirement,但是对于要求的服务器规格理解不到位。导致没有准确评估出现有集群规格无法满足部署条件。
- 集群再部署前内存水位线已接近临界值,但并没有被注意到。
- 集群挂掉之前,并没有灾备预案。导致恢复过程属于“摸石头过河”。
- 运维自动化程度不够,无论是重新拉起,还是恢复上层应用都需要手动操作。
经验教训
- 部署前一定要详细了解 Pre-requirement,做好风险分析
- 生产级集群在部署新应用前,要做容量估算和检查,预留好充足资源
- 生产级集群需要有灾备预案,并定期进行演练,以提高运维团队应对突发状况的能力
- 添加自动化运维能力,例如: Ansible, Terraform